כבר שמעתם על ה-IPO של Snowflake - חברת התוכנה שהנפיקה בשווי הכי גבוה אי פעם?

Co-Founder and CEO of iKnowlogy Ltd. - Data science and BI professional services.
יכול להיות ששמעתם על חברת Snowflake פעם ראשונה השבוע כאשר דווח על ה-IPO הכי גדול אי פעם של חברת תוכנה.
Snowflake הנפיקה ביום ד’ האחרון (17/9/2020) לפי שווי של 33B$ ועוד קפצה עד סוף המסחר לשווי מטורף של 71B$!!! רק בפברואר האחרון ניתן לה עוד שווי של 12.4B$ בסבב גיוס הון.
אז האמת שאנחנו באיינולוג’י לא היינו מופתעים בכלל.
כבר כשהתחלנו לעבוד עם Snowflake ב-2016 היה לנו ברור שמדובר ב-Game Changer. ולכן בשלב מאוחר יותר הפכנו גם ל-SI partner ואצל לקוחות רבים שלנו עשינו הטמעות מוצלחות.
אז מה בכלל החברה הזו עושה?
במשפט אחד – פלטפורמת (“ביג”) דטה בענן.
Snowflake זה שירות מנוהל שמאפשר לך לנהל את הדטה הארגוני שלך ביעילות וגם להשתמש בדטה לכל פתרון BI ו-Data science שתעלה על דעתך. השירות יושב מעל פלטפורמות הענן של AWS, Google ו-Azure ומתפקד כמחסן נתונים (Data-lake / DWH) עם חיבוריות נוחה לכל מקום שממנו צריך לשאוב נתונים.
מה מיוחד ב-Snowflake?
שלושה דברים עיקריים:
- צורת עבודה עם דטה ב-scale שעד כה הייתה שמורה רק לחברות גדולות עם כיסים קצת יותר עמוקים, נגישה עם Snowflake גם לחברות קטנות.
שימוש בשירות של Snowflake לעומת שימוש בשיטות ובכלים אחרים מפחית במידה עצומה את התלות של הארגון ב-data engineers. זה מאפשר ל-data analysts לעבוד בצורה הרבה יותר עצמאית כי הדטה הרבה יותר נגיש ואינו מצריך תחזוקה, פיתוח וניהול של דברים שנדרשים בעבודה עם כלים אחרים כמו Redshift, Bigquery, Vertica או דטה-בייסים רלציוניים ובוודאי לעומת כלים כמו Athena, Presto, Hadoop, Hive שבוודאי ובוודאי כדאי להחליף מיד ב-Snowflake (ואפשר להחליף ב-95% מהמקרים לדעתי).
כל feature שאתה נתקל בו בשימוש ב-Snowflake מפתיע אותך במידת הפשטות והנוחות שבה הוא מומש. עבור אנליסטים ו-data scientists זה כמו לנהוג על רולס-רויס.
קצת היסטוריה כדי להבין למה Snowflake זה Game-Changer
בשנת 2007 נכנסתי לתחום הדטה במקביל לכך שהתחלתי את התואר השני בסטטיסטיקה. עבדתי מטעם חברת G-Stat בפרוייקטים בבנק לאומי וב-YES. סביבת הדטה שעליה עבדתי באותם ימים הייתה ה-DWH (מחסן הנתונים). בכל חברה כזו ה-DWH היה שרת אחד גדול ומסיבי שמאפשר הרצה של שאילתות ותהליכי עיבוד דטה ב-SQL. זה היה עולם מאוד נוח, כל הנתונים הקיימים היו נגישים ב-SQL והיה אפשר לבנות תהליכי דטה מורכבים מאוד.
פלטפורמות ה-DWH שאפיינו את התקופה הזו היו Oracle, Teradata ו-MSSQL server.
שני תהליכים שהתרחשו במקביל כבר אז הלכו והתעצמו:
– עלייה של חברות און ליין שנותנות שירות למיליוני יוזרים מסביב לעולם (חברות מדיה, גיימינג, איקומרס ו-SaaS).
– התפתחות של שירותי הענן בדגש על AWS שהיו הראשונים לגדול ממש.
בשנת 2012 הצטרפתי לחברת און-ליין בתחום הE-Commerce ששירתה סדר גודל של 40M יוזרים ביום. עכשיו תחשבו על כמות הדטה שמייצרת חברת און ליין של 30 עובדים עם 40M יוזרים ביום לעומת כמות הדטה שמייצרת חברת בזק עם 6000 עובדים ו-2M לקוחות… אולי חברת האון-ליין יכולה לייצר יותר דטה אם לא בערך אותו הדבר לפחות. כבר אז כלי הענן התפתחו בצורה שהציעו טכנולוגיות שפותחו במקומות כמו Google, Yahoo ו-Facebook ואיפשרו לעבד כמויות גדולות של דטה. אבל זה היה ממש מסובך. פלטפורמת הדטה שלנו באותה חברת E-Commerce קטנה כללה שימוש בטכנולוגיות כגון Hive, Redshift, EMR. רדשיפט גם היה פריצת דרך כאשר יצא לשוק ב-2013 כי הוא איפשר לעשות את רוב הדברים ב-SQL פשוט מעליו. אבל לא יכלנו לשמור את כל הדטה שרצינו עליו בצורה נגישה כי זה היה יוצא יקר מידי, אז נאלצנו לפתח תהליכי data-engineering מורכבים כדי להוריד עלויות. עדיין העלות של תשתית הדטה הצטברה לסדר גודל של 200,000$ בשנה בלי לשקלל את עלות האנשים שהיו צריכים לתחזק את הדבר הזה.
בשנים הבאות הלכו והתפתחו כלים שקצת הקלו על העבודה ואיפשרו לעבוד ב-scale גבוה – Presto, Athena, Spark. אבל עדיין הכלים האלה מצריכים ידע פיתוחי שהפך להיות מה שנקרא data engineering. תפקיד ה-data engineer שאחראי לפיתוח תהליכי ETL ועיבוד של נתונים השתלב ב-echo-system של חברות הייטק ולעיתים גם כבש את טבלאות השכר ועקף תפקידים אחרים של פיתוח תוכנה.
ההנפקה של Snowflake מסמנת בעיני את סוף ה-Data Dark Ages מכיוון שניתן לחזור לשיטות העבודה המסורתיות והפשוטות ברוב המקרים. טעינת הנתונים ל-snowflake פשוטה, כל הדטה נגיש, אפשר לעבוד ב-scale והכל ב-SQL פשוט. באמצעות Snowflake, אנליסטים מוכשרים יכולים לבנות פתרונות data ב-SQL מקצה לקצה וכל העומס של ניהול תשתית big-data מורכבת יכול לרדת כמעט לגמרי. כבר לא נותרה כל כך הצדקה להטמיע שימוש בפלטפורמות שמבוססות על Spark, Presto, Hive, Hadoop, Athena וכו’ אלא לעבור לשירות מנוהל.
איך בנוי השירות של Snowflake?
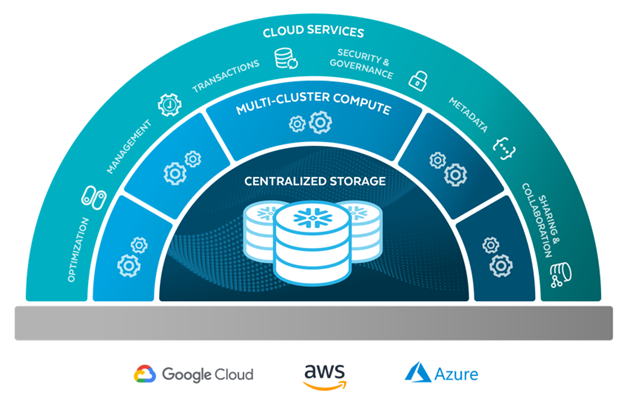
הפלטפורמה של Snowflake כוללת כמה רכיבים:
Centralized Storage
Snowflake מאפשר מקום אחד שממנו ניתן לנהל גם דטה חיצוני שיושב בקבצים וגם דטה שנטען לתוך Snowflake ונשמר בצורה אופטימלית לצורך שליפות מהירות. הדטה הזה נשמר כל העת במנותק משרתי העיבוד כך שהאיחסון שלו זול מאוד (מחירי S3 למביני עניין, 23$ לTB לחודש).Multi-Cluster Compute – שכבת העיבוד
הרכיב שמשמש לעיבוד הדטה (טעינת נתונים והרצת שאילתות) הוא שכבה עצמאית שניגשת לאיחסון ועובדת רק כאשר יש צורך לשלוף את המידע ומעבד אותו (למביני עניין – storage-compute decoupling).
בשכבה הזו מנהלים את המשאבים שמוקצים לעיבוד הדטה ובעצם אפשר להגדיר מה יהיה הכוח של הקלאסטרים של המכונות שיגשו לדטה ויעבדו אותם. בנוסף אפשר להגדיר הרבה קלאסטרים כאלה כך שהמון שירותים שונים יוכלו לעבוד על הדטה במקביל בלי לייצר עומס (מה שנקרא horizontal scalability). וגם על הגודל של כל קלאסטר כזה ניתן לשלוט (vertical scalability).Cloud Service
מעל המנוע האלגנטי של עיבוד הדטה יושבת שכבת השירותים שמאפשר לנהל הרשאות, לנהל שיתוף דטה עם חשבונות Snowflake של צד ג’, לנהל מטה-דטה, להתחבר לדטה חיצוני והכל בצורה אלגנטית ופשוטה.
לסיכום…
ההנפקה המטורפת של Snowflake, נותנת עוד חותמת לעובדה שהכלי הזה הוא Game Changer בעולם הדאטה.
אנחנו ממליצים בחום לחברות וארגונים שבונים את תשתית הדאטה לבנות אותה סביב Snowflake.
גם לחברות וארגונים שמשתמשים בכלים אחרים כדאי לשקול את המעבר ל-Snowflake – היעילות, הפשטות והעוצמה של הכלי הזה יגמדו את אי הנוחות של מעבר להטמעה של כלי חדש.
אם יש לכם שאלות לגבי Snowflake, או שאתם רוצים ללמוד עוד על הכלי הנפלא הזה – אתם מוזמנים לפנות אלינו.
אם אתם שוקלים הטמעה של Snowflake, אתם מוזמנים להנות מהניסיון שלנו בהקמת תשתית data ארגונית מבוססת Snowflake בארגונים קטנים וגדולים. צרו קשר ונשמח לייעץ ולעבוד.